
Stable Diffusion 3: Research Paper
Key Takeaways
Today, we’re publishing our research paper that dives into the underlying technology powering Stable Diffusion 3.
Stable Diffusion 3 outperforms state-of-the-art text-to-image generation systems such as DALL·E 3, Midjourney v6, and Ideogram v1 in typography and prompt adherence, based on human preference evaluations.
Our new Multimodal Diffusion Transformer (MMDiT) architecture uses separate sets of weights for image and language representations, which improves text understanding and spelling capabilities compared to previous versions of Stable Diffusion.

Following our announcement of the early preview of Stable Diffusion 3, today we are publishing the research paper which outlines the technical details of our upcoming model release. The paper will be accessible on arXiv soon, and we invite you to sign up for the waitlist to participate in the early preview.
Performance
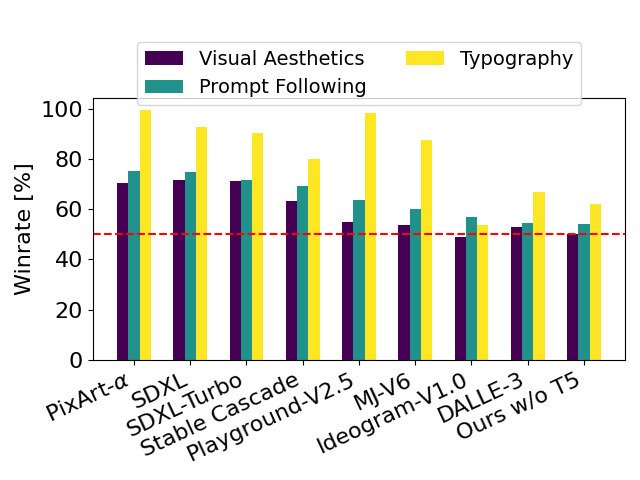
With SD3 as a baseline, this chart outlines the areas it wins against competing models based on human evaluations of Visual Aesthetics, Prompt Following, and Typography.
We have compared output images from Stable Diffusion 3 with various other open models including SDXL, SDXL Turbo, Stable Cascade, Playground v2.5 and Pixart-α as well as closed-source systems such as DALL·E 3, Midjourney v6 and Ideogram v1 to evaluate performance based on human feedback. During these tests, human evaluators were provided with example outputs from each model and asked to select the best results based on how closely the model outputs follow the context of the prompt it was given (“prompt following”), how well text was rendered based on the prompt (“typography”) and, which image is of higher aesthetic quality (“visual aesthetics”).
From the results of our testing, we have found that Stable Diffusion 3 is equal to or outperforms current state-of-the-art text-to-image generation systems in all of the above areas.
In early, unoptimized inference tests on consumer hardware our largest SD3 model with 8B parameters fits into the 24GB VRAM of a RTX 4090 and takes 34 seconds to generate an image of resolution 1024x1024 when using 50 sampling steps. Additionally, there will be multiple variations of Stable Diffusion 3 during the initial release, ranging from 800m to 8B parameter models to further eliminate hardware barriers.

Architecture Details
For text-to-image generation, our model has to take both modalities, text and images, into account. This is why we call this new architecture MMDiT, a reference to its ability to process multiple modalities. As in previous versions of Stable Diffusion, we use pretrained models to derive suitable text and image representations. Specifically, we use three different text embedders - two CLIP models and T5 - to encode text representations, and an improved autoencoding model to encode image tokens.
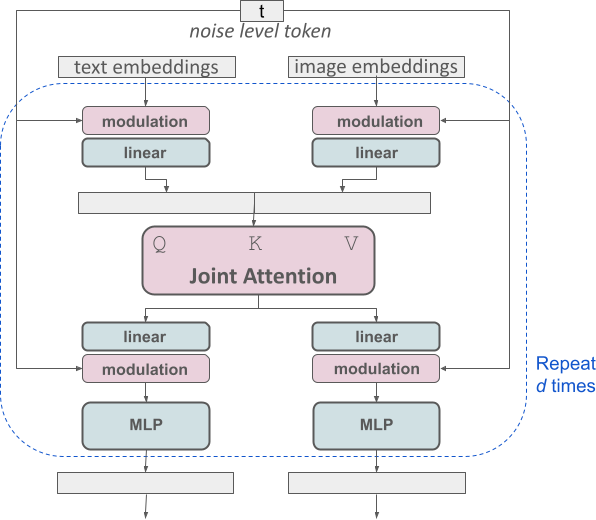
Conceptual visualization of a block of our modified multimodal diffusion transformer: MMDiT.
The SD3 architecture builds upon the Diffusion Transformer (“DiT”, Peebles & Xie, 2023). Since text and image embeddings are conceptually quite different, we use two separate sets of weights for the two modalities. As shown in the above figure, this is equivalent to having two independent transformers for each modality, but joining the sequences of the two modalities for the attention operation, such that both representations can work in their own space yet take the other one into account.
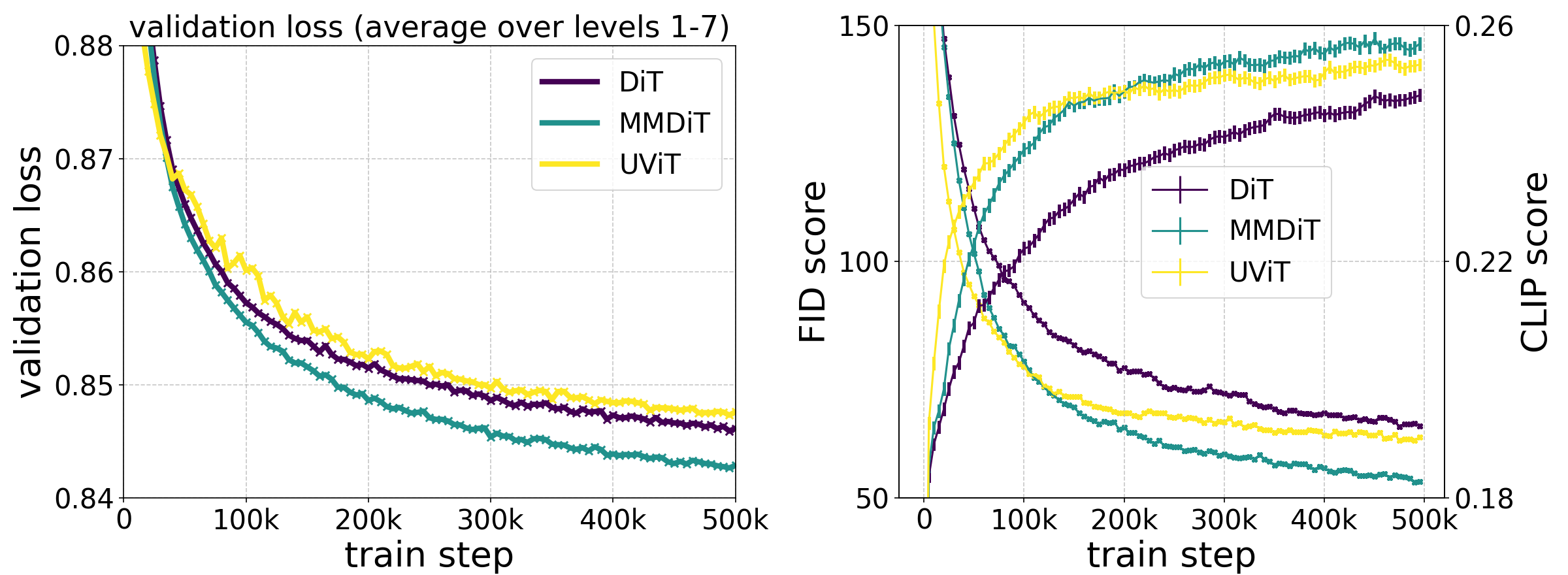
Our novel MMDiT architecture outperforms established text-to-image backbones such as UViT (Hoogeboom et al, 2023) and DiT (Peebles & Xie, 2023), when measuring visual fidelity and text alignment over the course of training.

Thanks to Stable Diffusion 3’s improved prompt following, our model has the ability to create images that focus on various different subjects and qualities while also remaining highly flexible with the style of the image itself.

Improving Rectified Flows by Reweighting
Stable Diffusion 3 employs a Rectified Flow (RF) formulation (Liu et al., 2022; Albergo & Vanden-Eijnden,2022; Lipman et al., 2023), where data and noise are connected on a linear trajectory during training. This results in straighter inference paths, which then allow sampling with fewer steps. Furthermore, we introduce a novel trajectory sampling schedule into the training process. This schedule gives more weight to the middle parts of the trajectory, as we hypothesize that these parts result in more challenging prediction tasks. We test our approach against 60 other diffusion trajectories such as LDM, EDM and ADM, using multiple datasets, metrics, and sampler settings for comparison. The results indicate that while previous RF formulations show improved performance in few step sampling regimes, their relative performance declines with more steps. In contrast, our re-weighted RF variant consistently improves performance.
Scaling Rectified Flow Transformer Models
We conduct a scaling study for text-to-image synthesis with our reweighted Rectified Flow formulation and MMDiT backbone. We train models ranging from 15 blocks with 450M parameters to 38 blocks with 8B parameters and observe a smooth decrease in the validation loss as a function of both model size and training steps (top row). To test whether this translates into meaningful improvements of the model outputs, we also evaluate automatic image-alignment metrics (GenEval) as well as human preference scores (ELO) (bottom row). Our results demonstrate a strong correlation between these metrics and the validation loss, indicating that the latter is a strong predictor of overall model performance. Furthermore, the scaling trend shows no signs of saturation, which makes us optimistic that we can continue to improve the performance of our models in the future.
Flexible Text Encoders
By removing the memory-intensive 4.7B parameter T5 text encoder for inference, SD3’s memory requirements can be significantly decreased with only small performance loss. Removing this text encoder does not affect visual aesthetics (win rate w/o T5: 50%) and results only in slightly reduced text adherence (win rate 46%) as seen in the above image under the “Performance” section. However, we recommend including T5 for using SD3’s full power in generating written text, since we observe larger performance drops in typography generation without it (win rate 38%) as seen in the examples below:

Removing T5 for inference only results in significant performance drops when rendering very complex prompts involving many details or large amounts of written text. The above figure shows three random samples per example.
To learn more about MMDiT, Rectified Flows, and the research behind Stable Diffusion 3, read our full research paper here.
To stay updated on our progress follow us on Twitter, Instagram, LinkedIn, and join our Discord Community.