
Introducing SDXL Turbo: A Real-Time Text-to-Image Generation Model
Key Takeaways:
SDXL Turbo achieves state-of-the-art performance with a new distillation technology, enabling single-step image generation with unprecedented quality, reducing the required step count from 50 to just one.
See our research paper for specific technical details regarding the model’s new distillation technique that leverages a combination of adversarial training and score distillation.
Download the model weights and code on Hugging Face, currently being released under a non-commercial research license that permits personal, non-commercial use.
Test SDXL Turbo on Stability AI’s image editing platform Clipdrop, with a beta demonstration of the real-time text-to-image generation capabilities.
Today, we are releasing SDXL Turbo, a new text-to-image mode. SDXL Turbo is based on a novel distillation technique called Adversarial Diffusion Distillation (ADD), which enables the model to synthesize image outputs in a single step and generate real-time text-to-image outputs while maintaining high sampling fidelity. For researchers and enthusiasts interested in technical details, our research paper is available here. It's important to note that SDXL Turbo is not yet intended for commercial use.
Advantages of Adversarial Diffusion Distillation
Featuring new advancements in diffusion model technologies, SDXL Turbo iterates on the foundation of SDXL 1.0 and implements a new distillation technique for text-to-image models: Adversarial Diffusion Distillation. By incorporating ADD, SDXL Turbo gains many advantages shared with GANs (Generative Adversarial Networks), such as single-step image outputs, while avoiding artifacts or blurriness often observed in other distillation methods. The SDXL Turbo research paper detailing this model’s new distillation technique is available here.
Performance Benefits Compared to Other Diffusion Models
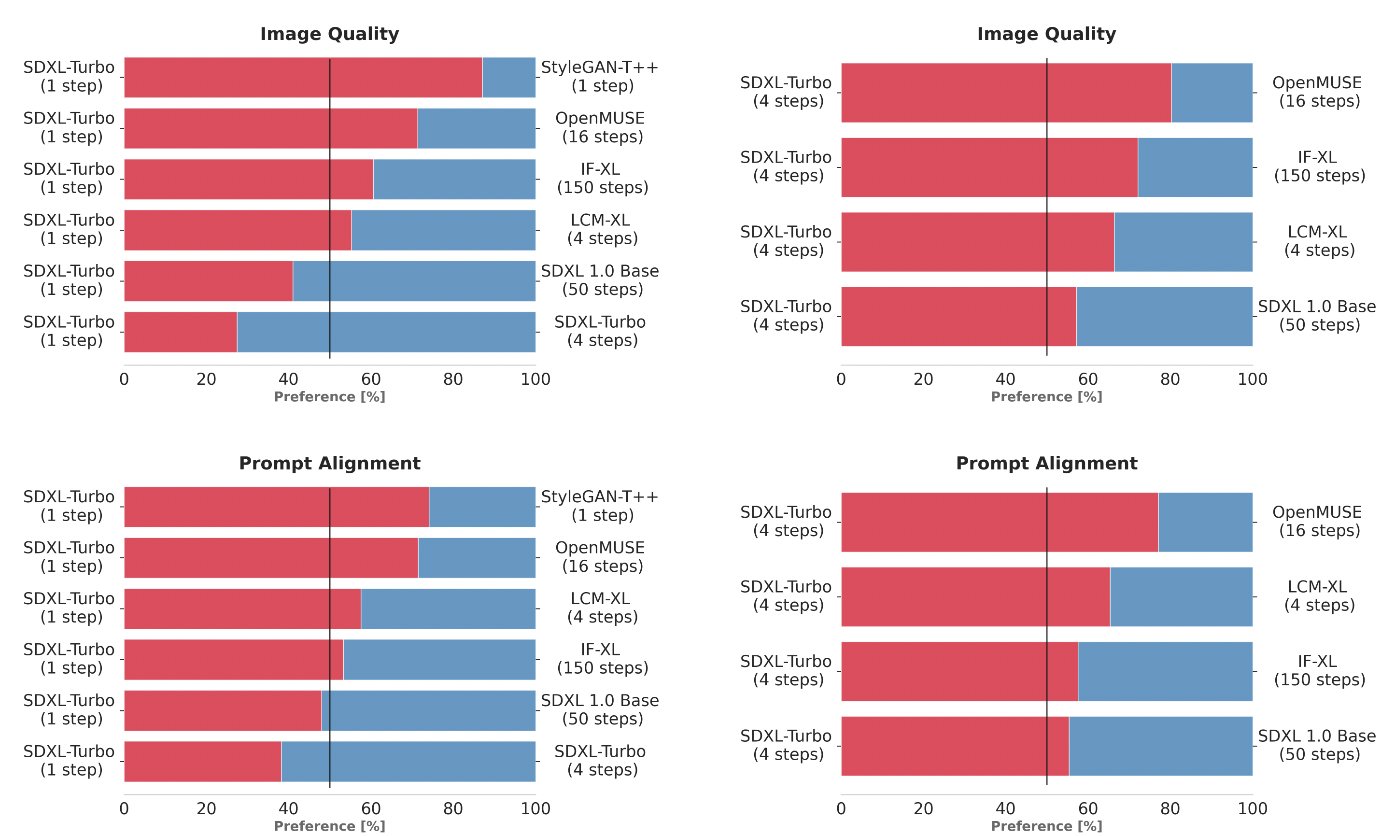
To make the selection for SDXL Turbo, we compared multiple different model variants (StyleGAN-T++, OpenMUSE, IF-XL, SDXL, and LCM-XL) by generating outputs with the same prompt. Human evaluators were then shown two outputs at random and tasked to pick the output that most closely followed the direction of the prompt. Next, an additional test was completed with the same method for image quality. In these blind tests, SDXL Turbo was able to beat a 4-step configuration of LCM-XL with a single step, as well as beating a 50-step configuration of SDXL with only 4 steps. With these results, we can see SDXL Turbo outperforming a state-of-the-art multi-step model with substantially lower computational requirements without sacrificing image quality.
Additionally, SDXL Turbo provides major improvements to inference speed. On an A100, SDXL Turbo generates a 512x512 image in 207ms (prompt encoding + a single denoising step + decoding, fp16), where 67ms are accounted for by a single UNet forward evaluation.
Explore SDXL Turbo with Clipdrop
To test the capabilities of this new model, visit Stability AI's image editing platform, Clipdrop, for a beta demonstration of SDXL Turbo's real-time image generation. It's compatible with most browsers and is currently available to try for free.
Commercial Applications
If you want to use this model for your commercial products or purposes, please contact us here to learn more.
You can also stay updated on our progress by signing up for our newsletter, following us on Twitter, Instagram, LinkedIn, and joining our Discord Community.