
Introducing Stable Cascade
Key Takeaways:
Today we are releasing Stable Cascade in research preview, a new text to image model building upon the Würstchen architecture. This model is being released under a non-commercial license that permits non-commercial use only.
Stable Cascade is exceptionally easy to train and finetune on consumer hardware thanks to its three-stage approach.
In addition to providing checkpoints and inference scripts, we are releasing scripts for finetuning, ControlNet, and LoRA training to enable users further to experiment with this new architecture that can be found on the Stability GitHub page.

Today we are launching Stable Cascade in research preview. This innovative text to image model introduces an interesting three-stage approach, setting new benchmarks for quality, flexibility, fine-tuning, and efficiency with a focus on further eliminating hardware barriers. Additionally, we are releasing training and inference code that can be found on the Stability GitHub page to allow further customization of the model & its outputs. The model is available for inference in the diffusers library.
Technical Details
Stable Cascade differs from our Stable Diffusion lineup of models as it is built on a pipeline comprising three distinct models: Stages A, B, and C. This architecture allows for a hierarchical compression of images, achieving remarkable outputs while utilizing a highly compressed latent space. Let’s look at each stage to understand how they come together:

The Latent Generator phase, Stage C, transforms the user inputs into compact 24x24 latents that are passed along to the Latent Decoder phase (Stages A & B), which is used to compress images, similar to what the job of the VAE is in Stable Diffusion, but achieving much higher compression.
By decoupling the text-conditional generation (Stage C) from the decoding to the high-resolution pixel space (Stage A & B), we can allow additional training or finetunes, including ControlNets and LoRAs to be completed singularly on Stage C. This comes with a 16x cost reduction compared to training a similar-sized Stable Diffusion model (as shown in the original paper). Stages A and B can optionally be finetuned for additional control, but this would be comparable to finetuning the VAE in a Stable Diffusion model. For most uses, it will provide minimal additional benefit & we suggest simply training Stage C and using Stages A and B in their original state.
Stages C & B will be released with two different models: 1B & 3.6B parameters for Stage C and 700M & 1.5B parameters for Stage B. It is recommended to use the 3.6B model for Stage C as this model has the highest quality outputs. However, the 1B parameter version can be used for those who want to focus on the lowest hardware requirements. For Stage B, both achieve great results, however, the 1.5 billion excels at reconstructing fine details. Thanks to Stable Cascade’s modular approach, the expected VRAM requirements for inference can be kept to approximately 20gb but can be further lowered by using the smaller variants (as mentioned before, this may also decrease the final output quality).
Comparison
During our evaluations, we found Stable Cascade performs best in both prompt alignment and aesthetic quality in almost all model comparisons. The figures show the results from a human evaluation using a mix of parti-prompts and aesthetic prompts:
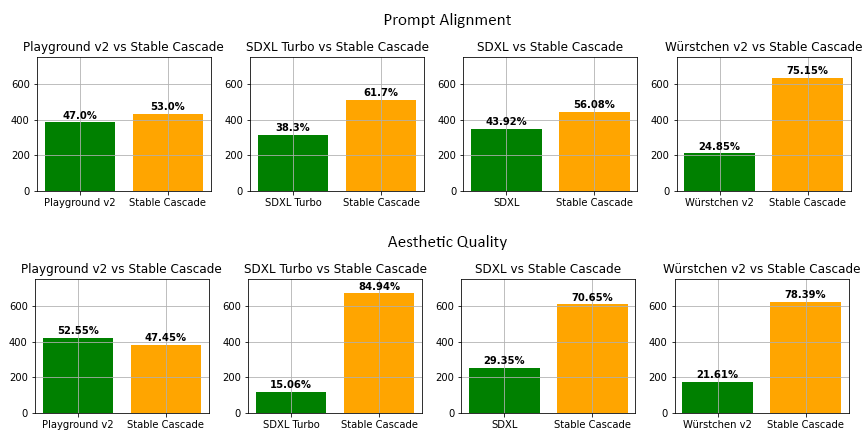
The above image compares Stable Cascade (30 inference steps) against Playground v2 (50 inference steps), SDXL (50 inference steps), SDXL Turbo (1 inference step) and Würstchen v2 (30 inference steps).

The above image demonstrates the differences in inference speed between
Stable Cascade, SDXL, Playground v2, and SDXL Turbo
Stable Cascade´s focus on efficiency is evidenced through its architecture and higher compressed latent space. Despite the largest model containing 1.4 billion parameters more than Stable Diffusion XL, it still features faster inference times, as seen in the figure below.
Additional Features
Next to standard text-to-image generation, Stable Cascade can generate image variations and image-to-image generations.
Image variations work by extracting image embeddings from a given image using CLIP and then returning this back to the model. Below you can see some example outputs. The left image shows the original, while the four to its right are the variations generated.

Image-to-image works by simply adding noise to a given image and then using this as a starting point for the generation. Here is an example for noising the left image and then running the generation from there.

Code for Training, Finetuning, ControlNet and LoRA
With the release of Stable Cascade, we are releasing all the code for training, finetuning, ControlNet, and LoRA to lower the requirements to experiment with this architecture further. Here are some of the ControlNets we will be releasing with the model:
Inpainting / Outpainting: Input an image paired with a mask to accompany a text prompt. The model will then fill the masked part of the image by following the text prompt provided.

Canny Edge: Generate a new image by following the edges of an existing image input to the model. From our testing, it can also expand upon sketches.

In the above image, the top sketches are input into the model to produce the outputs on the bottom.
2x Super Resolution: Upscale an image to 2x its side (for example, turning a 1024 x 1024 image into a 2048x2048 output) and can also be used on latents generated by Stage C.

The details for these can be found on the Stability GitHub page, including the training and inference code.
While this model is not currently available for commercial purposes, if you’d like to explore using one of our other image models for commercial use, please visit our Stability AI Membership page for self-hosted commercial use or our Developer Platform to access our API.
To stay updated on our progress follow us on Twitter, Instagram, LinkedIn, and join our Discord Community.