
Meet Stable Audio 3.0, the model family built for artistic experimentation with open-weight models
Key Takeaways:
We're releasing Stable Audio 3.0, a model family with open-weights music models that are trained on fully licensed data.
You own your outputs and can distribute and commercialize them under the Stability AI Community License, or the Enterprise License for organizations with more than $1M in revenue.
Key innovations include variable-length generation up to six minutes, and full song composition on portable devices.
Stable Audio 3.0 Small and Medium are available on Hugging Face. You can download the weights here.
Stable Audio 3.0 Large is available via the Stability AI API and self-hosting for enterprise deployments. Try it out here.

Today we're releasing Stable Audio 3.0, a model family trained on fully licensed data, designed to be the foundation for what the audio community builds next. Three of the models are open weights, free to download and build on.
Music has always evolved through the collective creativity of its community. Remix culture, interpolations, and mashups are how artists build on each other's work and push the art form forward. Generative audio will be no different. We want to foster the same kind of community-driven innovation in audio that we sparked in image generation with the launch of Stable Diffusion.
Stable Audio 3.0 is our open invitation to experiment with generative audio. We believe the best innovations are still waiting to be built.
Meet the Stable Audio 3.0 model family
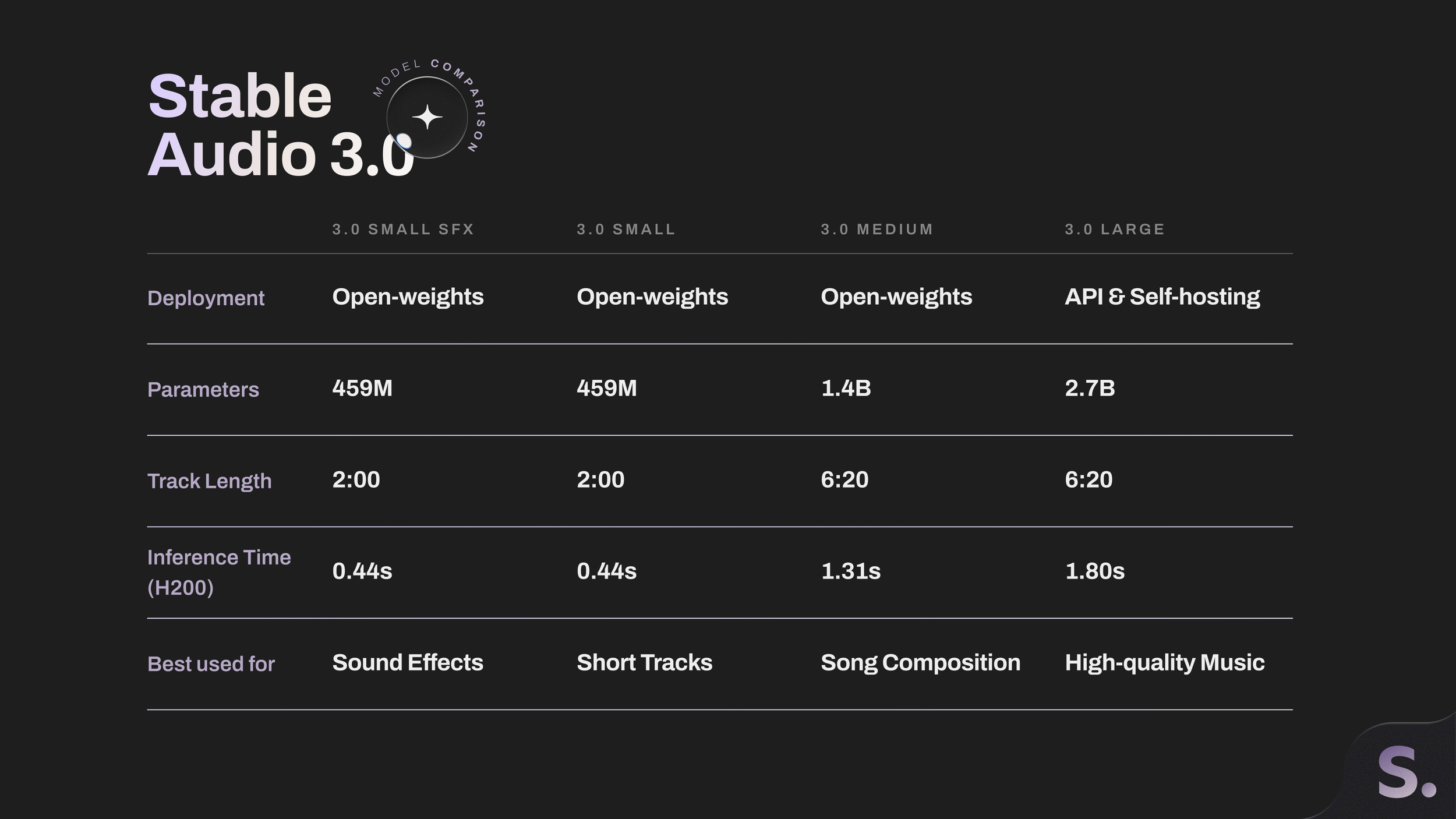
We’re releasing four new models designed for different use cases and deployment options:
Stable Audio 3.0 Small SFX: Sound effects generation on-device, such as mobile phones and consumer-grade laptops.
Stable Audio 3.0 Small: Full music composition on-device.
Stable Audio 3.0 Medium: Higher musicality (i.e. structure, melodic coherence, and phrasing) and longer track length at up to 6:20.
Stable Audio 3.0 Large: The most advanced musicality in the family, built for music platforms and creative applications that need low-latency generation at high volume.
Compare Stable Audio 3.0 Models
Open for experimentation, with ownership of what you create
All Stable Audio 3.0 models are trained on fully licensed data. Under the Stability AI Community License, you own your outputs and can distribute and commercialize them freely.
For organizations with more than $1M in annual revenue, you can get commercial coverage with our Enterprise license. We also offer legal indemnification under the Enterprise license.
3.0 Small SFX, 3.0 Small, and 3.0 Medium are all open-weights. To our knowledge, other open music models either restrict commercial use or carry the risks associated with being trained on unlicensed music.
Architectural advancements for variation and iteration
Stable Audio 3.0 is our next-gen architecture, built with a novel semantic-acoustic autoencoder that enables longer, more flexible audio generation. You can read the full research paper here.
Variable-length generation, up to more than six minutes. Stable Audio 3.0 introduces a new method for variable-length audio generation that enables you to generate exactly what you need, at per-second granularity.
3.0 Small generates up to two minutes, compared to 11 seconds from Stable Audio Open Small, and 47 seconds from Stable Audio Open. 3.0 Medium and 3.0 Large generate more than six minutes.
Full music composition on-device. To our knowledge, 3.0 Small is the only model capable of full music composition on-device. For the first time, on-device and offline audio generation isn't limited to short samples; it can produce complete musical tracks.
Customize the models on your own library with support for LoRa training. A LoRa is an efficient method for fine-tuning that was first made popular in image generation, and is now an emerging method for customizing audio generation models.
For the first time we're publishing documentation for LoRa training, alongside the weights for 3.0 Small and 3.0 Medium. For organizations with our Enterprise license, we offer the option of white-glove support with fine-tuning.
Audio inpainting options. Modify a segment of a track, rework part of a song, or extend your composition without starting over. Stable Audio 3.0 supports single-segment editing, multi-segment editing, and causal continuation (extending audio beyond its original endpoint).
Setting the stage for what’s next
Stable Audio 3.0 is the new architecture on which we're already building our next generation of fully licensed audio models for professionals.
While responsibly trained generative AI models are critical, they are not enough on their own. Artist-centric AI will only win if the product experience on a licensed platform is better than the experience on an unlicensed platform.
We're also working on a suite of new products for musicians. Join the waitlist to get early access.
In the meantime, you can learn more about our partnerships with Universal Music Group and Warner Music Group.
Get started with Stable Audio 3.0 now
Open weights: Download 3.0 Small SFX, 3.0 Small, and 3.0 Medium on Hugging Face. For organizations with more than $1M in annual revenue, contact us to discuss our Enterprise Licensing.
API: Stable Audio 3.0 Large is available via the Stability AI API.
Partner platforms: Stable Audio 3.0 will be available on ComfyUI and other platforms.
To stay updated on our progress, follow us on X, LinkedIn, Instagram, and join our Discord Community.